官方文档:http://azkaban.github.io/
Azkaban主要的组成:1. 关系型数据库——MySQL2. AzkabanWebServer3. AzkabanExcutorServer 使用MySQL存储状态,AzkabanWebServer和AzkabanExcutorServer访问数据库。AzkabanWebServer主要管理者Azkaban,主要进行了项目管理、身份验证、调度和监控执行。并且为用户界面。 使用方法:登录Azkaban环境登录账号和密码之后将会看到一个项目列表界面。点击创建项目就可以创建安新的项目,创建名称可以第一次命名之后不能再次改变,项目描述可以改变。创建好项目之后,就会进入项目界面,如果没有相关按钮,则说明用户没有相关权限,现在为一个空项目。
上传项目,点击Upload就可以上传项目,项目可以上zip文件,zip里需要包含*.job文件和其他需要运行的job。Job名称必须唯一。
创建流程:
Job为一条在Azkaban中运行的进程。这些Job可以依赖于其他Job。一组Job和他们的所依赖构成了Flow先创建job文件,文件后缀为*.job。1 #test.job2 type=command #job类型为command3 command=echo "hello world" #command用来执行命令
创建一个流程:
一个流程是一个依赖其他job的job。其他依赖项经常会运行在这个流程job之前。1 #this is flow bar.job2 type=command3 dependencies=test4 command=echo bar
在Azkaban中,type值得是运行的类型,command指的是一条Linux命令,同时Azkaban还支持python,java等直接运行,也就可以是hadoop的shell。
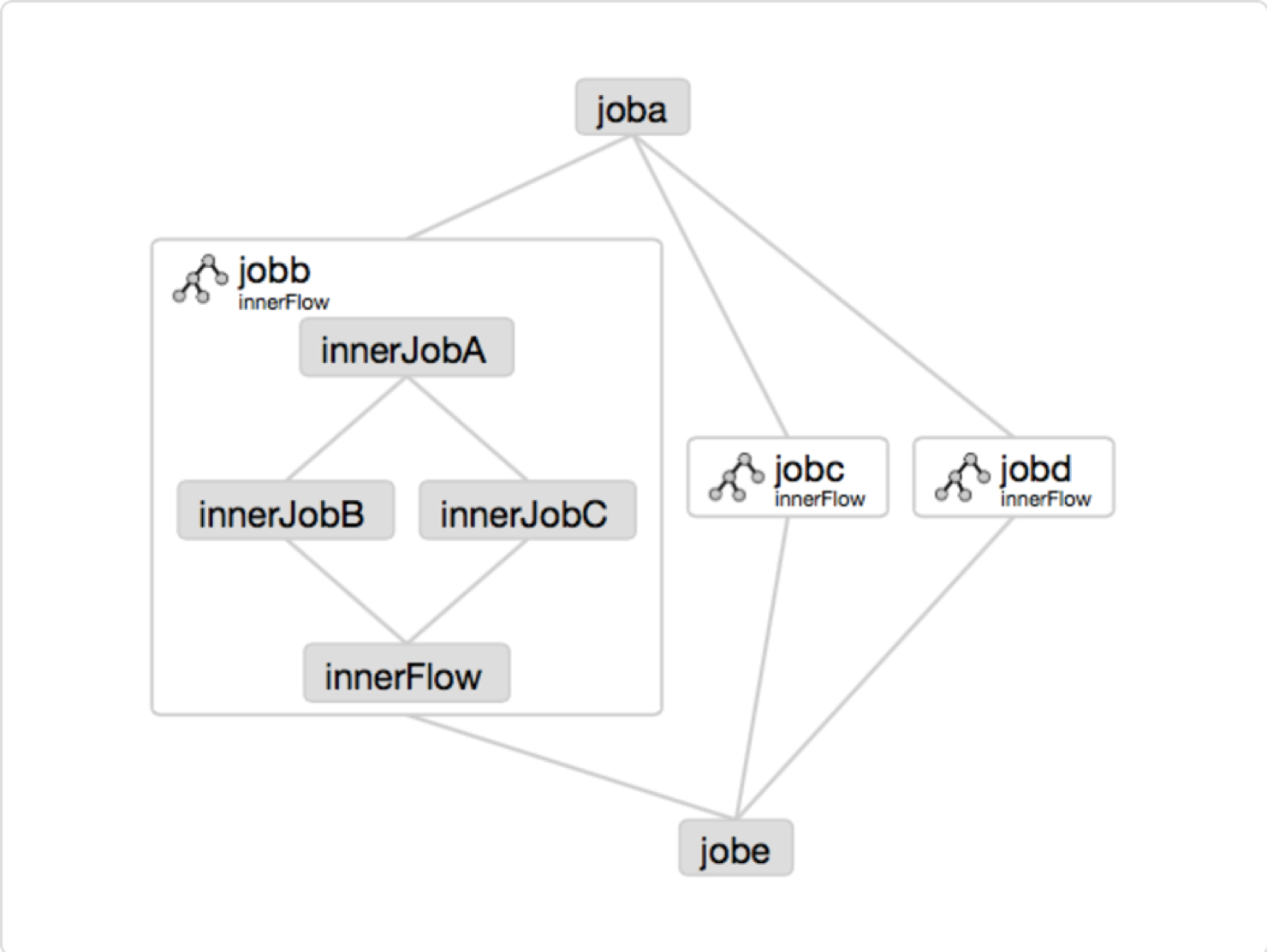
一个流程也可以作为一个节点嵌入到其他job文件中,形成嵌入流
type=flowflow.name=bar
1 #!/bin/bash2 echo "hello world"
文件aztest.job
1 # aztest.job2 type=command3 command=sh test.sh
文件zatest.properties
user.to.proxy=Hadoop
将这三个文件打包为zip包:
zip aztestlh.zip aztest.job aztest.properties test.sh
然后上传文件到Azkaban
上传完成值后就可以看到相关信息了
点击Execute Flow就可以运行
运行成功之后,图的底色会变成绿色:
查看日志信息可以看到我们之前的shell脚本输出的内容:
运行job的另一个方式就是定时,也就类似于cron,一个Azkaban项目就是定时脚本执行的调度器。一个Flow的例子:
定义多个job以及job之间的依赖就可以组成flow。定义依赖可以使用dependencies参数就可以了。例如创建了4个job:1 start.job 2 type=command 3 command=echo "start execute" 4 test.job 5 type=command 6 command=echo "Hello World" 7 sleep.job 8 type=command 9 dependencies=test, start10 finish.job11 type=command12 dependencies=sleep
有着四个job文件组成的为一个流,我们可以看到流的组成方式为job相互依赖的,将该Flow上传上去之后,Azkaban会将该流里的job以图的形式展示出来。
PS:Azkaban在执行完毕之后说的成功和失败,指的是job文件的成功和失败,并不是job文件所执行的其他文件失败与否。
发送邮件
Azkaban为我们的提供了任务执行的job结果成功失败的邮件提示。Azkaban为我们提供了3种执行发送消息的选择,分别为失败了发送邮件,失败发送短信和成功发送邮件。可以进行相关设置在对应的时候发送相关信息。